1. 커버링 인덱스란?
커버링 인덱스(Covering Index)는 인덱스 자체에 쿼리에서 필요한 모든 컬럼이 포함되어 있어 테이블 데이터를 조회하지 않고 인덱스만으로 결과를 반환할 수 있는 인덱스입니다.
커버링 인덱스의 특징
- WHERE 조건과 SELECT 컬럼 모두를 인덱스에 포함시킵니다.
- 테이블 접근이 제거되므로 랜덤 I/O 비용이 줄어들어 성능이 크게 향상됩니다.
일반 인덱스와의 차이
- 일반 인덱스: WHERE 조건을 최적화하지만 SELECT 컬럼이 인덱스에 없으면 테이블 데이터를 추가로 조회해야 합니다.
- 커버링 인덱스: 모든 조건과 결과 컬럼이 인덱스에 포함되므로 테이블 접근 없이 바로 결과를 반환합니다.
2. 커버링 인덱스를 적용한 성능 비교
테스트 환경
- 데이터 개수: 10만 개
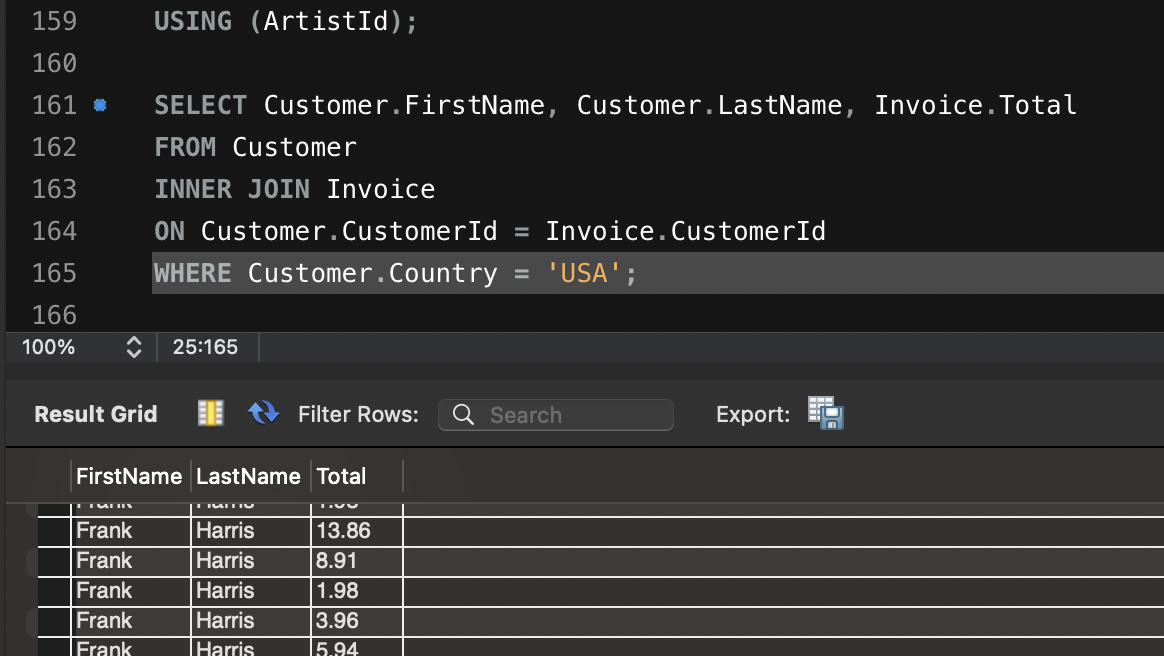
- 조회 조건: WHERE grade = 'SILVER' AND gender = 'Male'
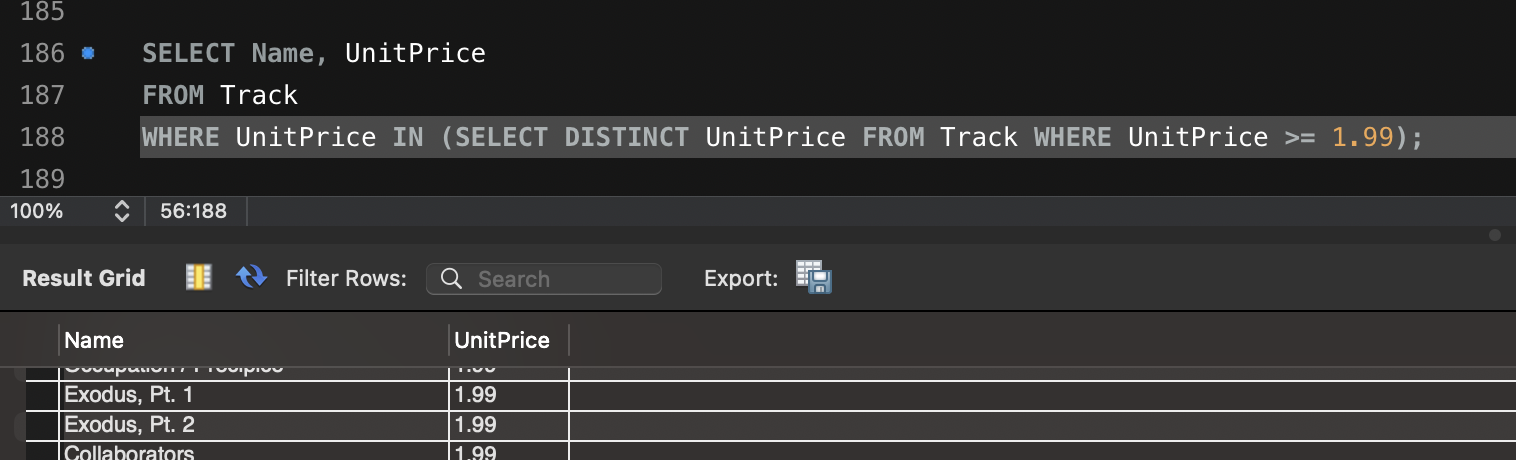
- 쿼리: SELECT * FROM customer WHERE grade = 'SILVER' AND gender = 'Male' LIMIT 0, 20000;
3. 단계별 성능 비교
단계인덱스 유형스캔된 행 수실제 반환된 행 수비용 (cost) 실행 시간특징
| 1. 인덱스 적용 전 | 없음 (ALL) | 99,256 | 12,562 | 10,238 | 65.5ms | 테이블 전체 스캔 |
| 2. 단일 컬럼 인덱스 | idx_grade | 49,628 | 12,562 | 3,420 | 44.7ms | gender 조건 추가 필터링 발생 |
| 3. 멀티컬럼 인덱스 | idx_grade_gender | 24,436 | 12,562 | 3,382 | 36.6ms | grade와 gender 조건 인덱스 처리 |
| 4. 커버링 인덱스 | idx_covering_all_columns | 24,392 | 12,562 | 3,377 | 34.9ms | 테이블 접근 없이 인덱스에서 결과 반환 |
4. 단계별 분석
1. 인덱스 적용 전 (테이블 전체 스캔)
- 인덱스 없음: 테이블 전체를 스캔하며 조건에 맞는 데이터를 필터링합니다.
- 스캔된 행 수: 99,256개
- 비용: 10,238
- 실행 시간: 65.5ms
- 결론: 성능이 가장 나쁘며, 테이블 전체 스캔으로 인해 I/O 비용이 큽니다.
2. 단일 컬럼 인덱스 (idx_grade)
- 인덱스 사용: grade 컬럼만 최적화됨. gender 조건은 추가 필터링이 발생합니다.
- 스캔된 행 수: 49,628개
- 비용: 3,420
- 실행 시간: 44.7ms
- 결론: 스캔된 행 수가 절반으로 줄었지만, gender 조건이 추가로 처리되므로 완벽한 최적화는 되지 않았습니다.
3. 멀티컬럼 인덱스 (idx_grade_gender)
- 인덱스 사용: grade와 gender 조건을 동시에 최적화합니다.
- 스캔된 행 수: 24,436개
- 비용: 3,382
- 실행 시간: 36.6ms
- 결론: 두 조건을 인덱스에서 처리하면서 추가 필터링 비용이 제거되어 성능이 크게 개선되었습니다.
4. 커버링 인덱스 (idx_covering_all_columns)
- 인덱스 사용: WHERE 조건 최적화 + 모든 컬럼이 인덱스에 포함되어 테이블 접근이 제거되었습니다.
- 스캔된 행 수: 24,392개
- 비용: 3,377
- 실행 시간: 34.9ms
- 특징:
- Using index가 실행 계획에 나타남.
- 인덱스만으로 모든 데이터를 반환 → 랜덤 I/O 최소화.
- 결론: 가장 빠른 성능을 보여주며, 테이블 접근 비용이 완전히 제거되었습니다.

5. 결론 및 추천
성능 개선 순서
- 인덱스 적용 전 → 성능이 가장 낮음 (테이블 전체 스캔).
- 단일 컬럼 인덱스 → WHERE 조건 일부만 최적화되므로 추가 필터링 비용 발생.
- 멀티컬럼 인덱스 → 두 조건을 동시에 최적화.
- 커버링 인덱스 → WHERE + SELECT를 인덱스만으로 처리해 성능이 가장 좋음.
최적화 추천
모든 컬럼이 필요한 경우: 커버링 인덱스가 가장 효율적입니다.
CREATE INDEX idx_covering_all_columns ON customer (grade, gender, birth, created_date, is_deleted, visit_cnt, employee_id, id, address(50), email(50), memo(50), name(50), phone(20));INSERT/UPDATE 성능 저하를 감안해야 하므로 읽기 중심 테이블에 적용하는 것이 좋습니다.
'SQL > 성능 최적화' 카테고리의 다른 글
| 복합 인덱스로 성능 최적화하기 (0) | 2024.12.17 |
|---|---|
| MySQL 인덱스 적용 후에도 속도는 그대로인 이유 (0) | 2024.12.17 |