SQL 서브쿼리는 쿼리 내부에 중첩된 또 다른 쿼리입니다. 서브쿼리는 외부 쿼리와 함께 실행되며, 특정 조건을 만족하는 데이터를 조회하거나 값을 계산하는 데 사용됩니다. 이 글에서는 SQL 서브쿼리의 개념과 활용 방법을 살펴보겠습니다.
1. 서브쿼리 개념
- 서브쿼리(Subquery)는 SQL 쿼리 내부에서 실행되는 쿼리입니다.
서브쿼리는 외부 쿼리(메인 쿼리)의 입력으로 사용되며, SELECT, FROM, WHERE 절 등 다양한 위치에서 활용할 수 있습니다.
기본 문법
SELECT 컬럼명
FROM 테이블명
WHERE 컬럼명 = (서브쿼리);
예제
- 가장 비싼 트랙의 가격 조회
SELECT MAX(UnitPrice) AS MaxPrice
FROM Track;
- 가장 비싼 트랙의 가격과 동일한 트랙 조회
SELECT Name, UnitPrice
FROM Track
WHERE UnitPrice = (SELECT MAX(UnitPrice) FROM Track);2. 단일 행 서브쿼리
단일 행 서브쿼리는 하나의 값만 반환합니다. 보통 = 연산자와 함께 사용됩니다.
예제
- 가장 비싼 트랙의 이름 조회
SELECT Name
FROM Track
WHERE UnitPrice = (SELECT MAX(UnitPrice) FROM Track);- 가장 최근에 등록된 고객의 이름 조회
SELECT FirstName, LastName
FROM Customer
WHERE CustomerId = (SELECT MAX(CustomerId) FROM Customer);3. 다중 행 서브쿼리
다중 행 서브쿼리는 여러 개의 값을 반환합니다. 주로 IN, ANY, ALL 등의 연산자와 함께 사용됩니다.
예제
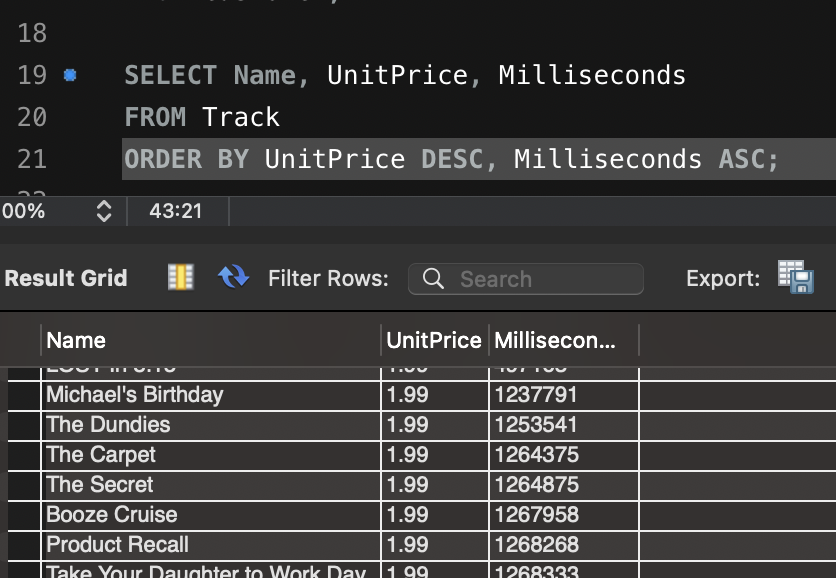
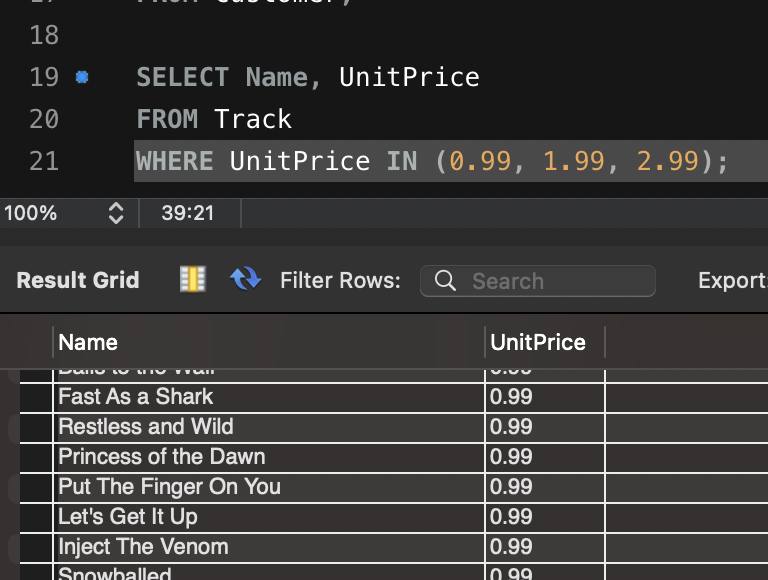
- 특정 가격($1.99, $2.99) 이상의 트랙 조회
SELECT Name, UnitPrice
FROM Track
WHERE UnitPrice IN (SELECT DISTINCT UnitPrice FROM Track WHERE UnitPrice >= 1.99);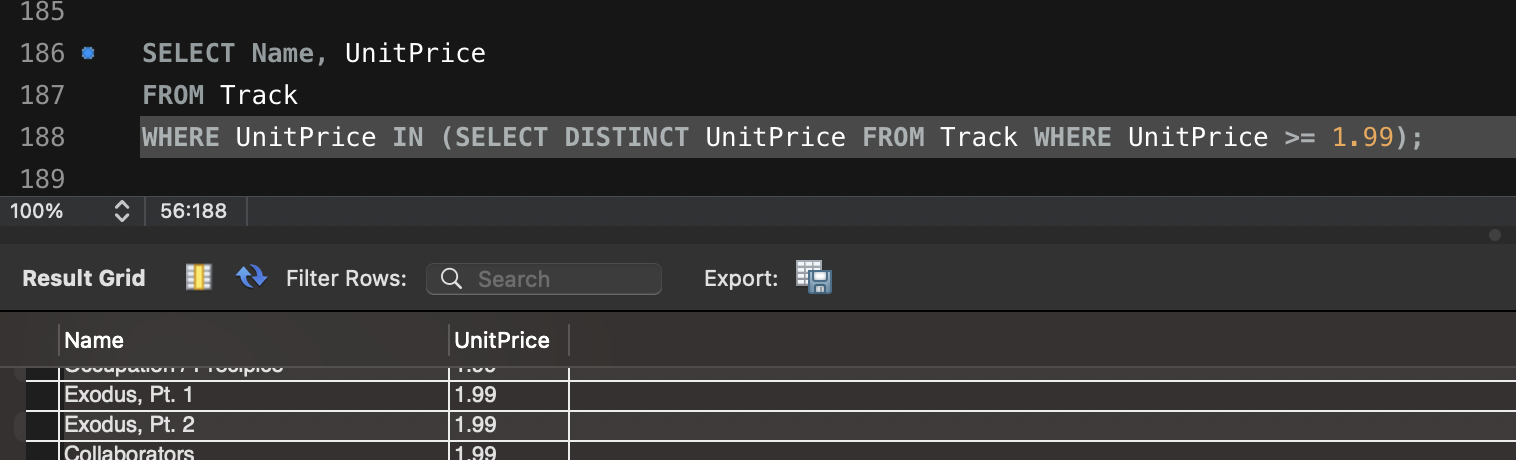
- 모든 트랙보다 비싼 가격의 트랙 조회
SELECT Name, UnitPrice
FROM Track
WHERE UnitPrice > ALL (SELECT UnitPrice FROM Track);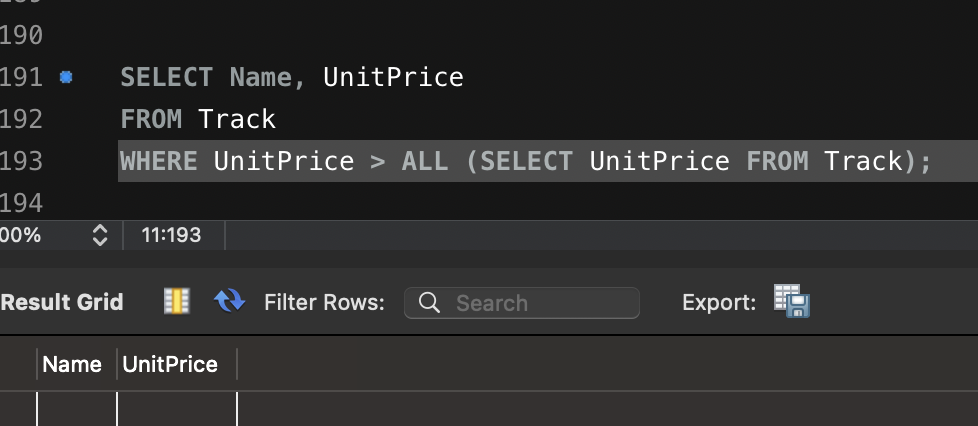
- 어떤 트랙보다 비싼 가격을 가진 트랙 조회
SELECT Name, UnitPrice
FROM Track
WHERE UnitPrice > ANY (SELECT UnitPrice FROM Track WHERE GenreId = 1);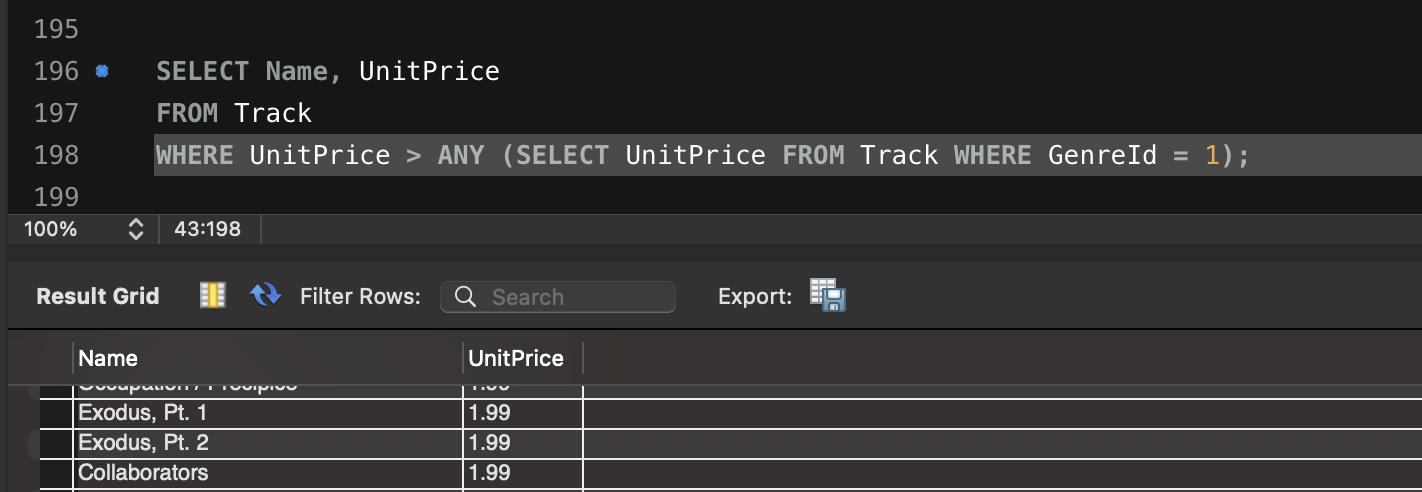
4. EXISTS와 NOT EXISTS
EXISTS는 서브쿼리의 조건에 맞는 데이터가 존재하는지 확인하며, NOT EXISTS는 데이터가 존재하지 않을 경우를 확인합니다.
기본 문법
SELECT 컬럼명
FROM 테이블명
WHERE EXISTS (서브쿼리);
예제
- 청구서가 있는 고객 조회
SELECT FirstName, LastName
FROM Customer
WHERE EXISTS (SELECT 1 FROM Invoice WHERE Customer.CustomerId = Invoice.CustomerId);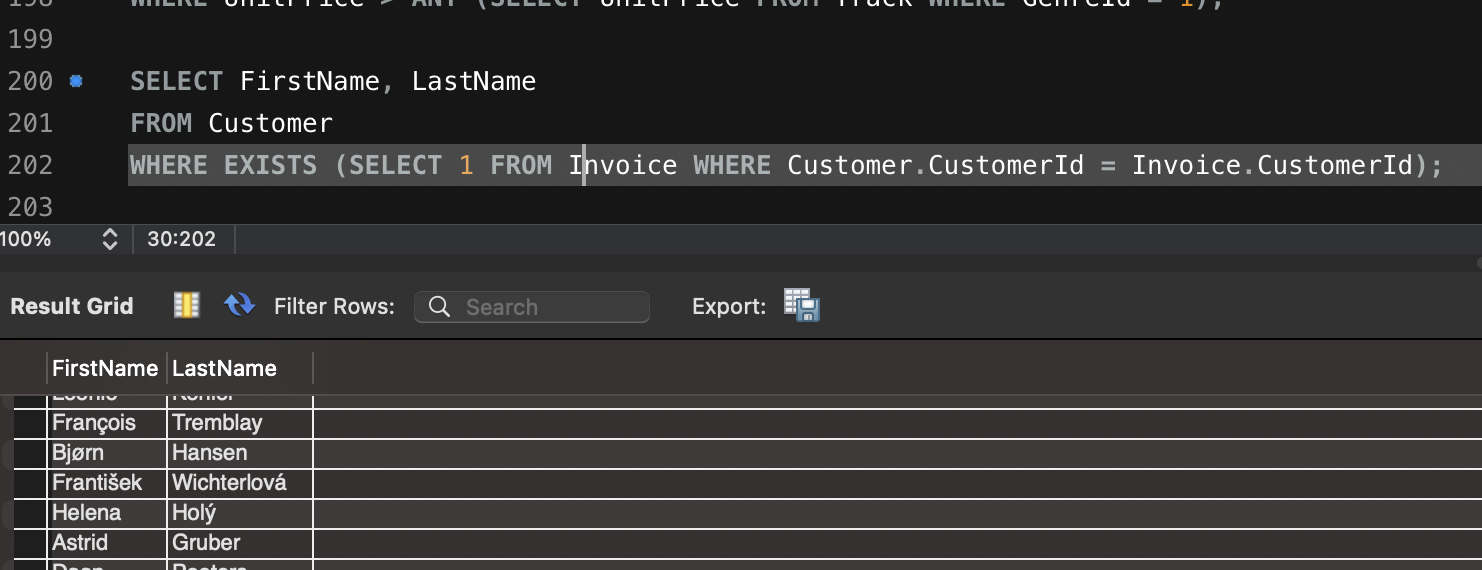
- 청구서가 없는 고객 조회
SELECT FirstName, LastName
FROM Customer
WHERE NOT EXISTS (SELECT 1 FROM Invoice WHERE Customer.CustomerId = Invoice.CustomerId);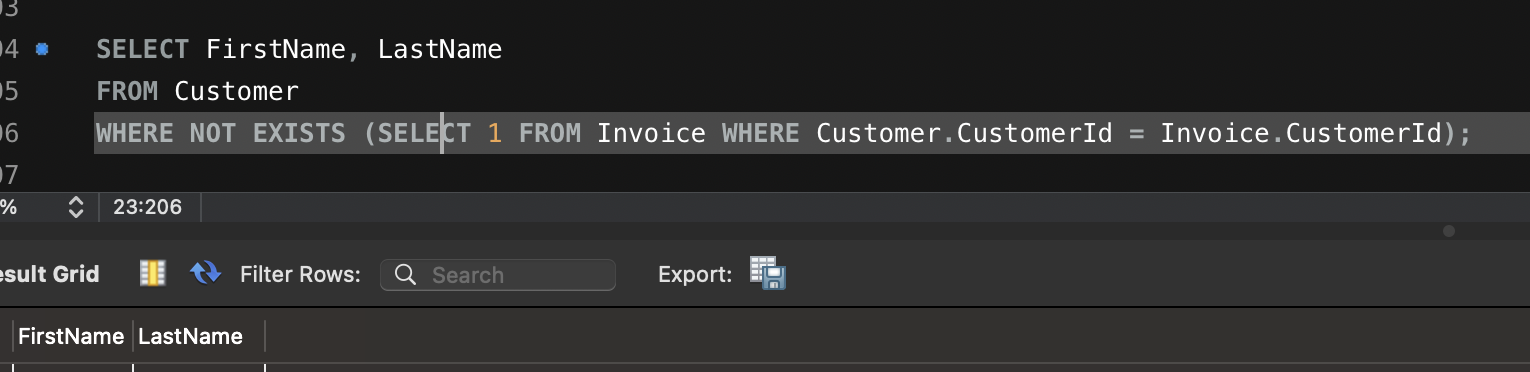
서브쿼리 사용 위치
1. SELECT 절에서 서브쿼리
서브쿼리를 SELECT 절에서 사용하여 계산된 값을 출력할 수 있습니다.
예제
- 각 트랙의 가격이 가장 비싼 트랙의 몇 퍼센트인지 계산:
SELECT Name,
UnitPrice,
(UnitPrice / (SELECT MAX(UnitPrice) FROM Track)) * 100 AS PricePercentage
FROM Track;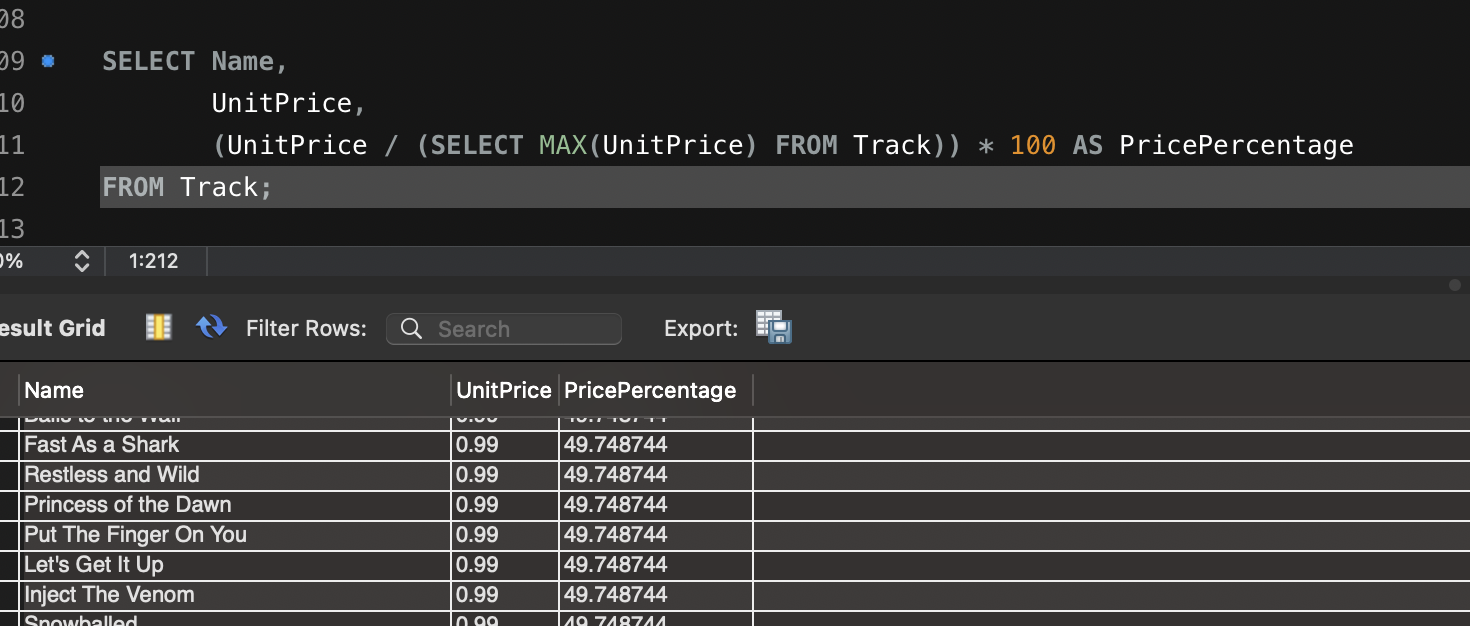
2. FROM 절에서 서브쿼리
서브쿼리를 FROM 절에서 사용하여 임시 테이블처럼 활용할 수 있습니다.
예제
- 장르별 평균 가격 계산:
SELECT GenreId, AVG(UnitPrice) AS AvgPrice
FROM (SELECT GenreId, UnitPrice FROM Track) AS Subquery
GROUP BY GenreId;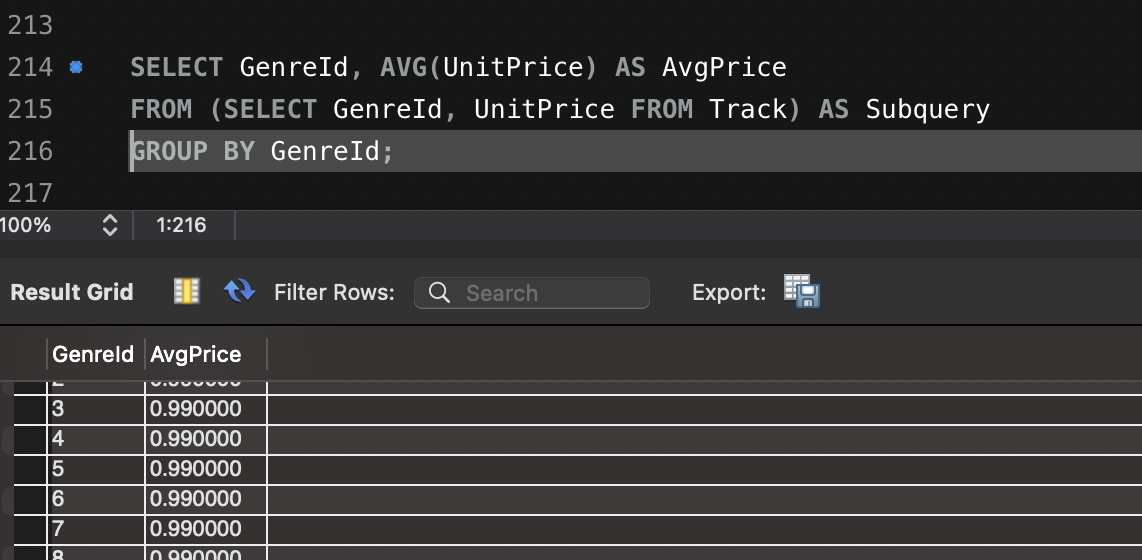
3. WHERE 절에서 서브쿼리
서브쿼리를 WHERE 절에서 사용하여 특정 조건에 맞는 데이터를 필터링합니다.
예제
- 가장 높은 평균 가격을 가진 장르의 트랙 조회:
SELECT Name
FROM Track
WHERE GenreId = (SELECT GenreId FROM Track GROUP BY GenreId ORDER BY AVG(UnitPrice) DESC LIMIT 1);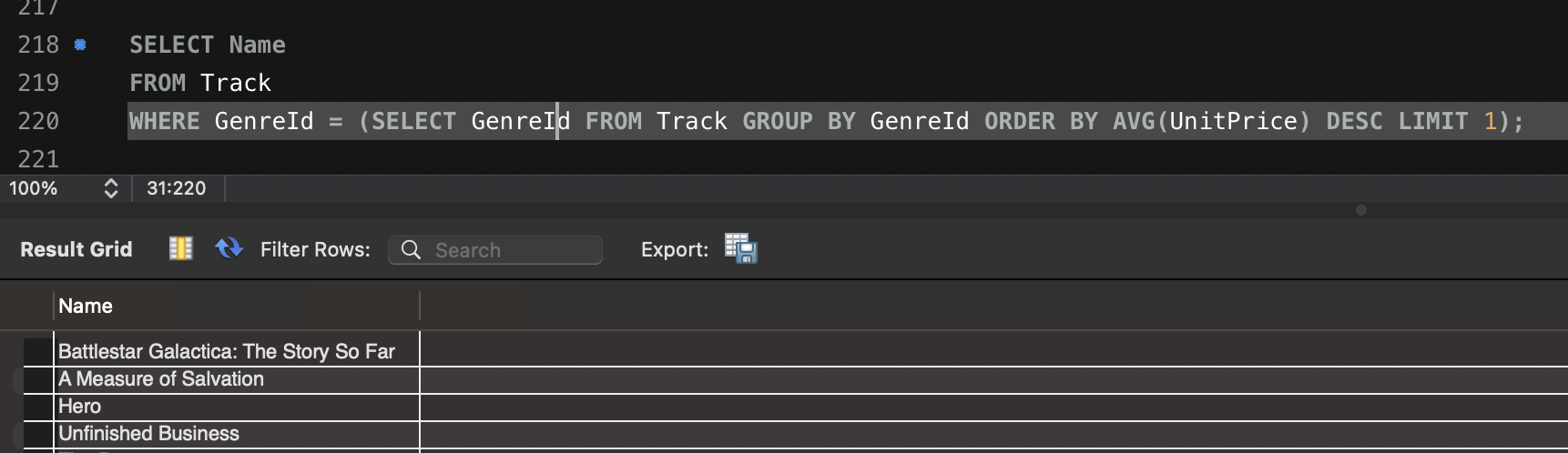
요약
- 단일 행 서브쿼리: 하나의 값을 반환하며, = 연산자와 함께 사용.
- 다중 행 서브쿼리: 여러 값을 반환하며, IN, ANY, ALL과 함께 사용.
- EXISTS와 NOT EXISTS: 조건 존재 여부를 확인하여 데이터를 필터링.
- 사용 위치: SELECT, FROM, WHERE 절 등 다양한 위치에서 활용 가능.
서브쿼리는 데이터 조회를 보다 정교하게 수행할 수 있도록 도와줍니다. 다음 글에서는 SQL 복합 쿼리를 통해 여러 쿼리를 조합하는 방법을 학습하겠습니다.
'SQL > 학습정리' 카테고리의 다른 글
| SQL 트랜잭션과 롤백 (1) | 2024.12.15 |
|---|---|
| SQL 복합 쿼리 (0) | 2024.12.14 |
| SQL Join (0) | 2024.12.11 |
| SQL 집계함수 (0) | 2024.12.10 |
| SQL 기본 문법 2 (0) | 2024.12.09 |