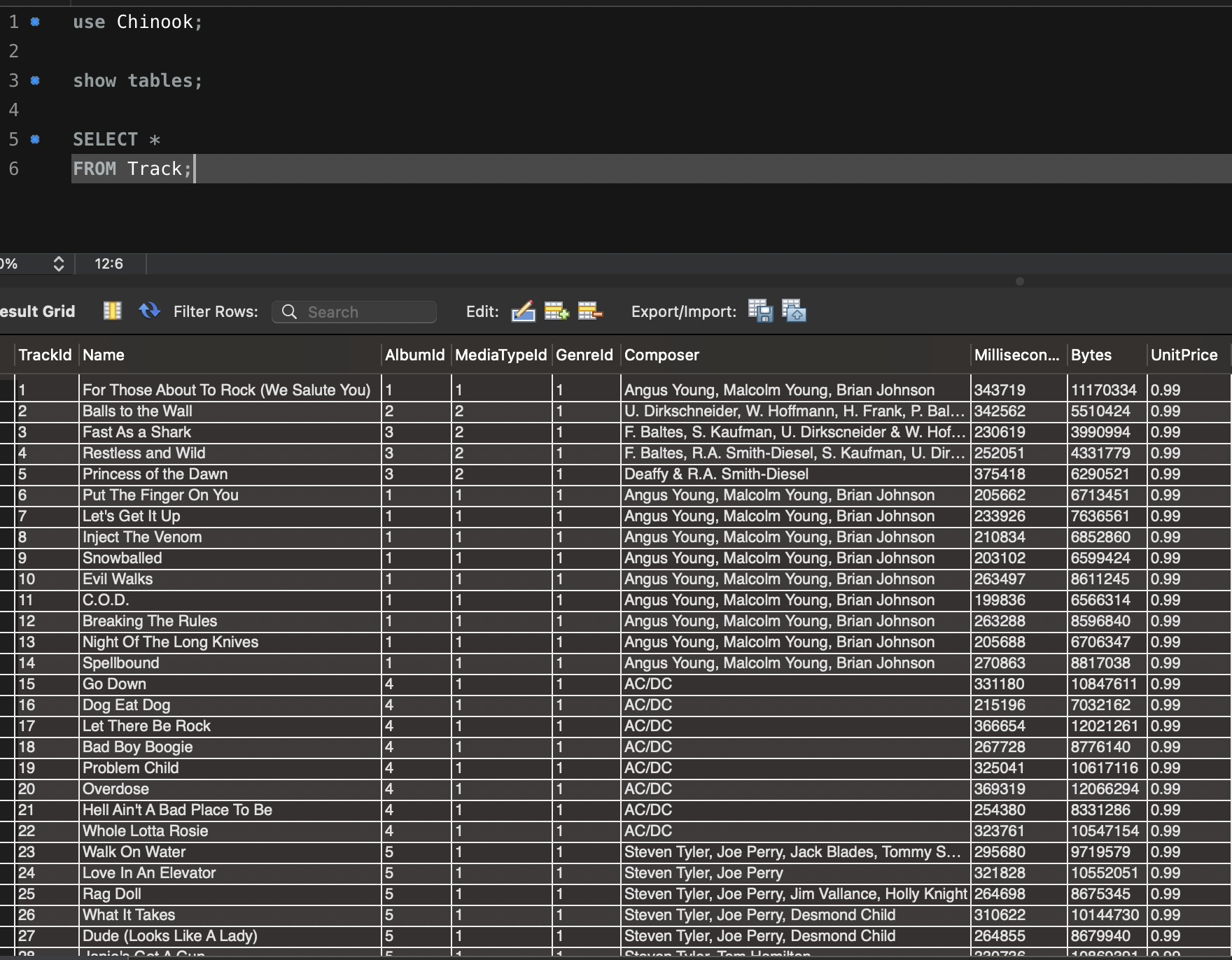
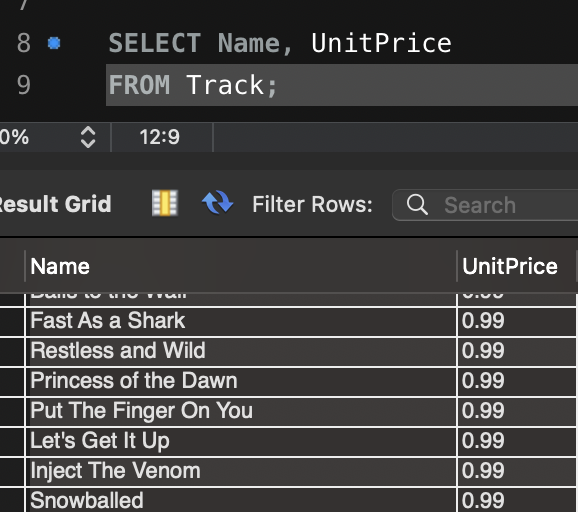
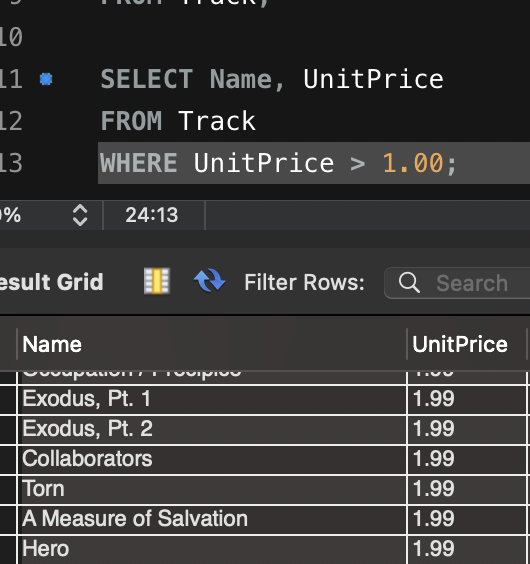
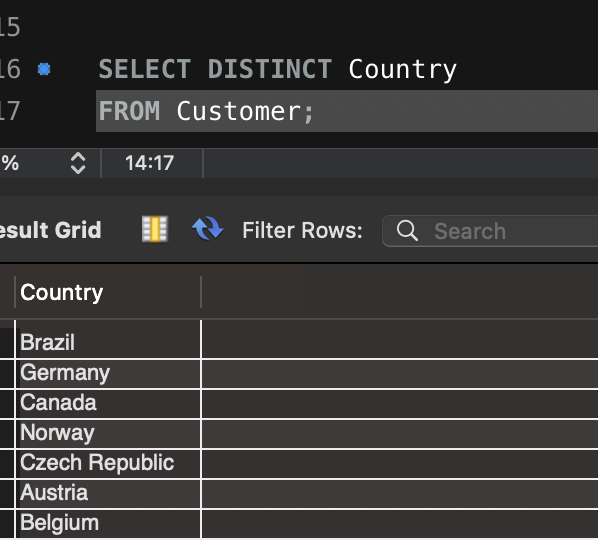
욕설 필터링 시스템을 설계할 때 다양한 방법론과 기술적인 선택지가 존재합니다. 저는 프로젝트를 진행하면서 욕설 필터링을 구현하기 위해 여러 접근 방식을 조사했고, 각각의 장단점을 비교해 보았습니다. 그 결과, 단순한 데이터베이스 기반 필터링부터 시작해, 정규 표현식을 활용한 필터링을 구현하는 방식을 선택했습니다.
1. 욕설 필터링의 일반적인 방법
욕설 필터링을 구현하는 방법은 크게 두 가지로 나눌 수 있습니다.
- 데이터베이스 기반 필터링
- 욕설과 비속어를 데이터베이스에 저장하고, 입력된 텍스트를 이 데이터와 비교해 감지하는 방식입니다.
- 구현이 간단하고 빠르게 결과를 도출할 수 있지만, 데이터베이스 크기에 따라 성능이 저하될 수 있습니다.
- 방대한 욕설 데이터베이스가 필요하며, 새로운 욕설이나 변형된 표현에 대한 대응이 어렵습니다.
- 자연어 처리 기반 필터링
- 머신러닝 또는 딥러닝 모델을 활용해 욕설을 감지하는 방식입니다.
- 문맥을 이해하고 변형된 욕설도 감지할 수 있는 장점이 있지만, 구현이 복잡하며 모델 학습에 많은 데이터와 리소스가 필요합니다.
2. 데이터베이스 기반 필터링 적용
욕설 필터링을 가장 빠르게 구현할 수 있는 방법은 데이터베이스에 욕설 데이터를 저장하고 이를 비교하는 방식입니다.
초기에 단순한 구현을 위해 욕설 데이터베이스를 직접 만들어 활용했으며, 기본적으로 다음과 같은 과정을 통해 처리했습니다.
욕설 데이터 수집
- 기본 욕설 목록 추가:
초기에는 간단한 욕설 단어를 데이터베이스에 직접 추가하여 테스트를 진행했습니다. - 확장 가능한 욕설 데이터베이스 조사:
이후 필터링의 정확도를 높이기 위해, 방대한 욕설 데이터베이스를 제공하는 자료들을 조사했습니다.
대표적으로 아래와 같은 자료들이 있었습니다: - 현실적 한계:
그러나 이러한 방대한 데이터를 실제 프로젝트에 바로 적용하기에는 리소스와 성능 문제가 발생할 수 있어, 현재 프로젝트에서는 단순한 데이터베이스로 시작했습니다.
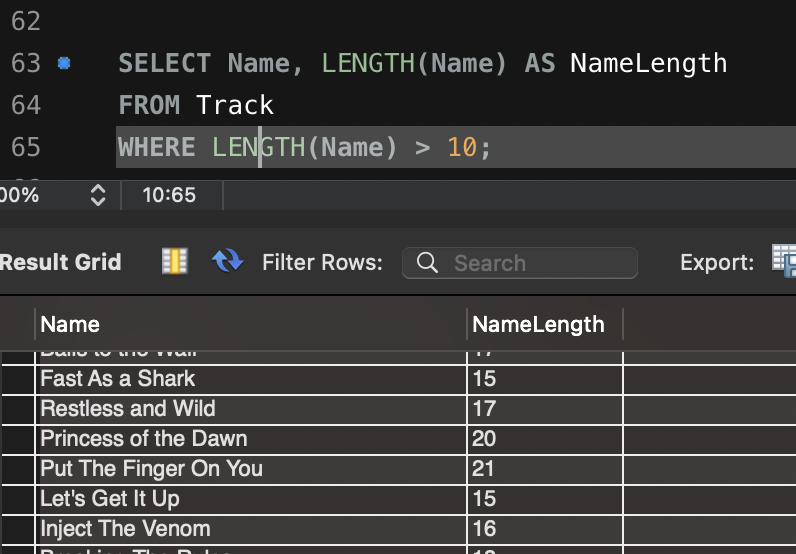
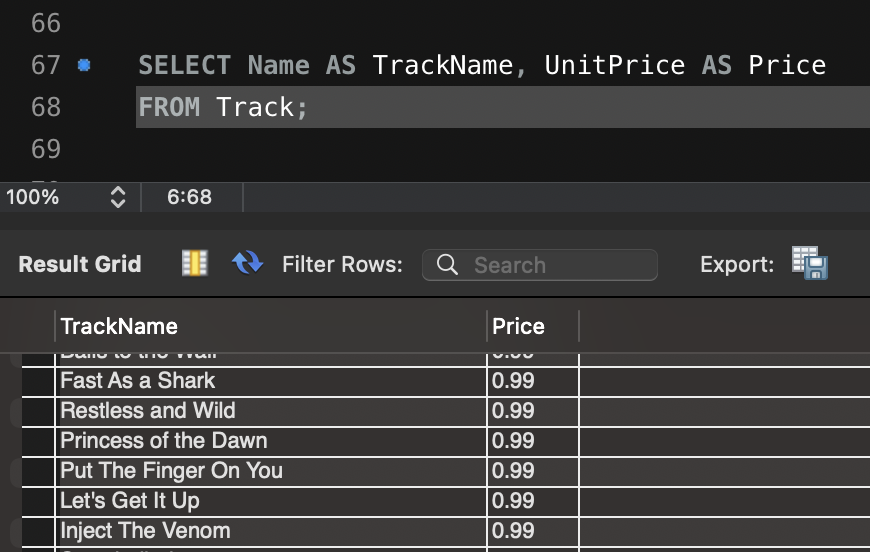
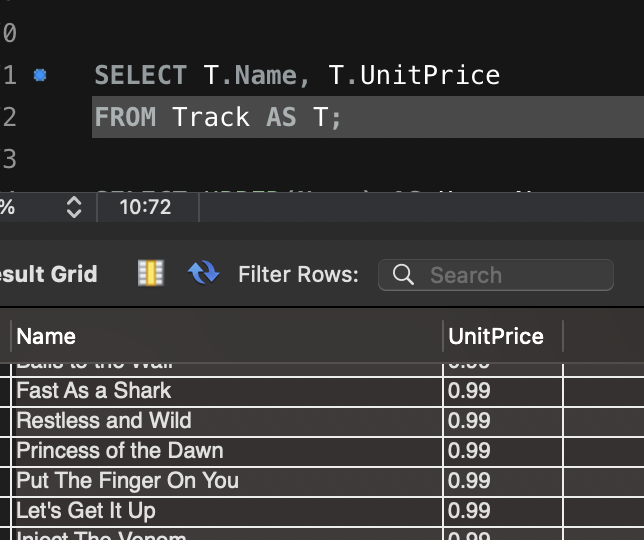
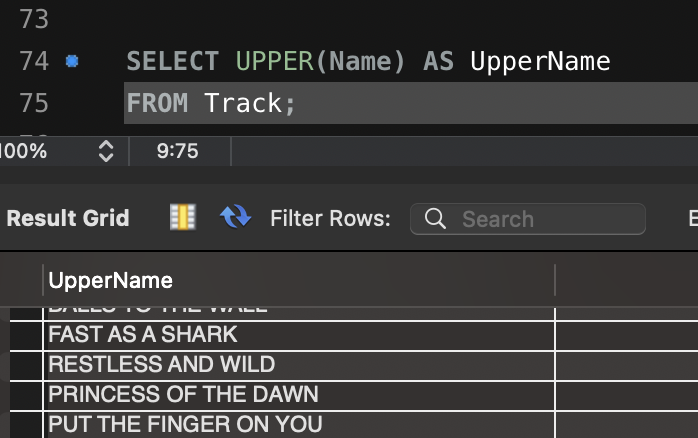
3. 정규 표현식을 활용한 욕설 필터링
욕설 데이터베이스 기반 필터링은 초기 구현 단계에서는 유용하지만, 성능 문제와 변형된 욕설(예: 띄어쓰기, 특수문자 사용)에 대한 대응이 부족하다는 한계가 있습니다. 이를 보완하기 위해 정규 표현식(Regex)을 활용한 필터링 로직을 구현해 보았습니다.
정규 표현식 적용 과정
- 욕설 패턴 정의:
- 바보, 멍청이 같은 단순한 욕설을 포함한 기본 패턴 작성.
- 욕설 단어 변형(예: 바ㅂㅗ, 멍청@이)을 감지하기 위해 다양한 정규 표현식을 작성.
- 구현 예시:
@Service
@Transactional
@RequiredArgsConstructor
public class ProfanityFilterService {
private final ProfanityRepository profanityRepository;
public List<String> getPatterns() {
return profanityRepository.findAll().stream()
.map(Profanity::getPattern)
.toList();
}
public String filter(String text, List<String> patterns) {
System.out.println("Original text: " + text);
String filteredText = text;
for (String pattern : patterns) {
Pattern compiledPattern = Pattern.compile("(?i)" + pattern, Pattern.UNICODE_CASE);
if (compiledPattern.matcher(text).find()) {
filteredText = compiledPattern.matcher(filteredText).replaceAll("****");
}
}
return filteredText;
}
}
4. 결론
욕설 필터링은 데이터베이스 기반의 간단한 구현부터 시작해 점진적으로 고도화할 수 있습니다. 초기 단계에서는 정규 표현식을 활용해 간단하게 필터링 로직을 작성했으며, 이후 확장성을 고려해 다음과 같은 방향으로 발전시킬 계획입니다.
- 방대한 욕설 데이터를 포함하는 데이터베이스와 결합.
- 사용자 경험을 고려한 실시간 필터링 로직 추가.
'Spring Framework > batch' 카테고리의 다른 글
| Clean Bot(욕설 필터링)은 실시간으로 일어나야 할까 (0) | 2024.12.08 |
|---|